


A very frequent operation in the AI space is to convert ‘something’ into a ‘vector’. This transformation of something into a vector is called an embedding. By using vectors you could maintain different semantic insights of the ‘something’ and you could utilize a lot of vector operations from linear algebra, like compare this ‘something’ into ‘some_other_thing’. For example you embed a text into a vector, then you embed another text into a vector and now you could compare the semantic meaning of those vectors.
In his great book “Build LLM from scratch” Sebastian Raschka nails the definition
“At its core an embedding is a mapping from discrete objects, such as words, images and even entire documents, to points in a continuous vector space”.
Each part of the vector is essentially capturing some meaning and nuances of the word. The gpt-3 model uses an embedding size of 12, 288 dimensions. If you are after a visualization here is a 3 dimension vector. We need 3 points to build the vector. Now good luck with 12, 288 dimensions.
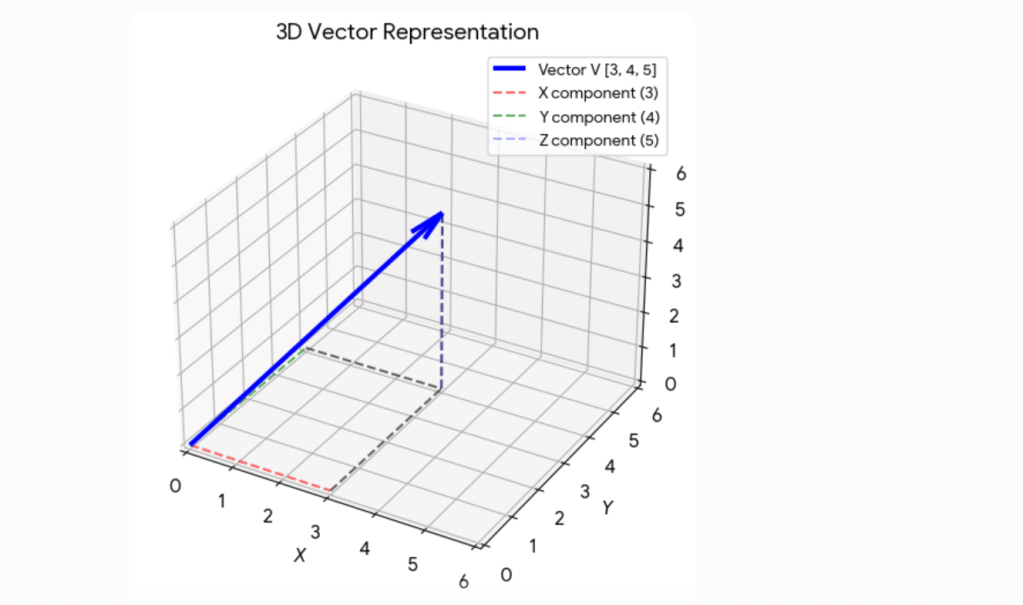
You could capture some nuances and meaning about a word in 3 dimensions as well.
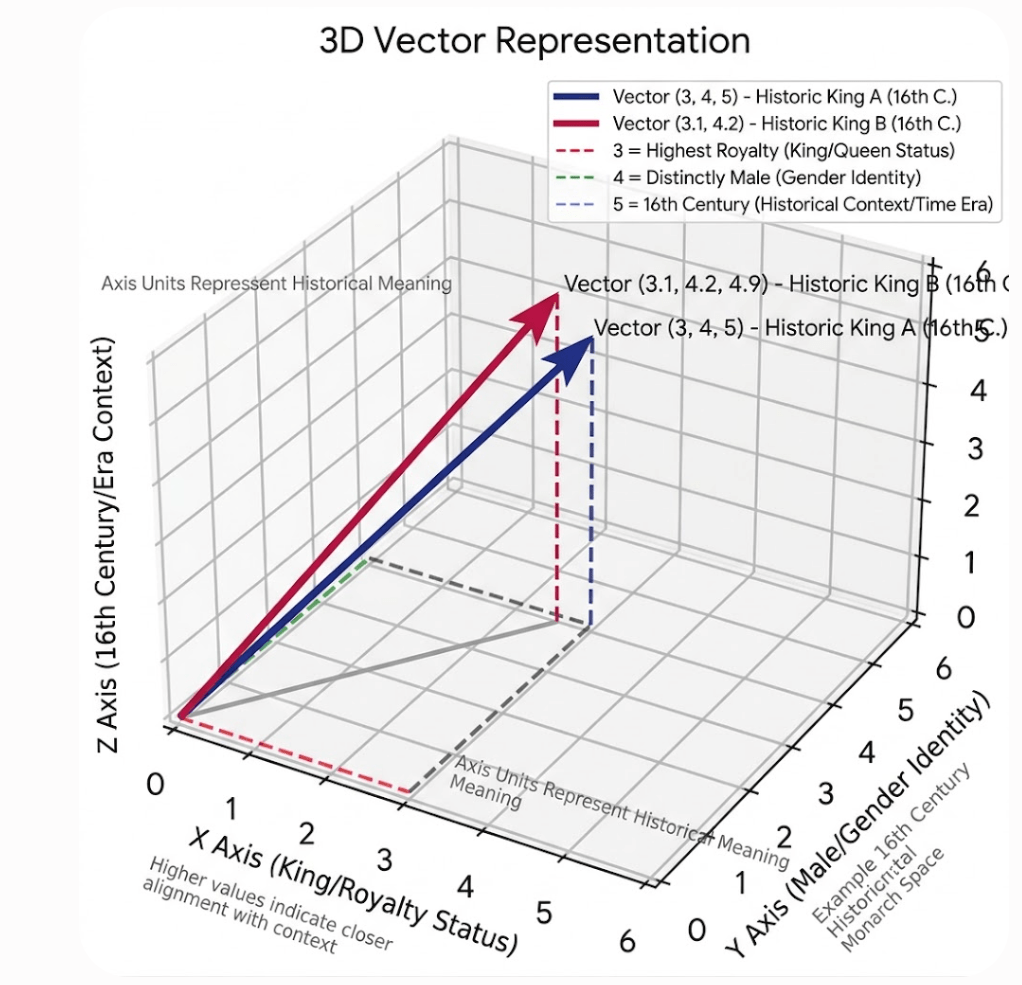
For example if we consider the 3D blue vector coordinates [3,4,5] as a legend that maps
- 3 = royality
- 4 = gender identity
- 5 = 16th century
and there is another king that was a male and was controlling the lands during 16th century we could have another vector ( in another color ) that would land very close to the blue one.
If you do some form of semantic search using vectors this is the operation that’s being applied. Now this is great that we could visualize those things and by far our understanding is much better with geometry, but when you are splitting the input to an LLM into tokens and then those tokens are being embedded, usually it would be expressed as a normal list. Something like:
[3,4,5] for a single token.
If we have an input towards the LLM model with a few words we are talking about more tokens. Is there a convinient way to group those tokens ? Yes, that’s correct we could build a matrix of the vectors, since each token is embedded. The only additional piece that we have not convered before the input is processed by the LLM is that inside each vector we also have an encoded position for that token, like where does it stand in the whole input. So if we would have to simplify it and we image the transformer as a function, the function input would be a big matrix. Each row will be a token and each column would capture some nuance and semantic.
[
[3,4,5]
[3.1,4.1,5.1]
]
Again in reality you would have much more features that capture some form of meaning and nuances, and also encoded token position among those values.
Transformer land is going to be the next topic. We are going to capture the self attention part, feed forward part and also how this cycle is being repeated multiple times to end up with the probability distribution about what’s the next most likely token. The reason for this understanding is that when we are picking up models from Hugging face we need to be aware about the layers, how they are stacked up, what exactly number of parameters mean …

Leave a comment